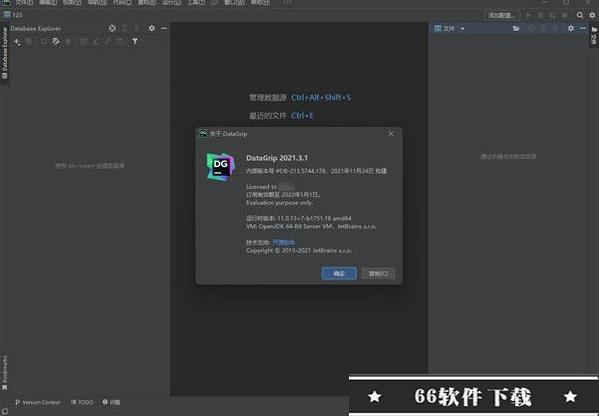
DataGrip 2021.3,一款非专业人员几乎不会遇到的软件。它是一款数据库管理软件,有着各种专业的数据库管理功能。目前流行的数据库产品,该软件几乎都能对其进行管理,比如DB2.Derby、H2.MySQL、Oracle、PostgreSQL、SQL Server、Sqllite和Sybase等。对于专业从事数据库开发的人员来说,该软件完全可以成为一个好帮手。像是数据库中常用到的创建和修改表、管理列、键以及索引的操作使用该软件都将更加方便。此次更新的2021.3更是带来了许多新增功能和改进。增强的功能有对数据编辑器、将数据库保留在 VCS 中、连接性等方面的增强;新增的功能有,新的数据库差异窗口,它能够将用户的DDL数据源与真实数据源比较和同步,摈弃请使用上下文菜单。随着软件的不断更新相信只会有更多出色的新增功能为提高用户的工作效率而服务。此次带来的是DataGrip 2021.3中文破解版。同时它也是该软件目前的最新版。
安装教程(附破解教程)
1.解压数据包后得到,得到安装程序和破解文件夹;
2.双击“datagrip-2021.3.1.exe”,开始对软件进行安装;
3.自定义软件安装目录后点击下一步;
4.等待软件安装完成,无需花太长时间;
5.点击finish即可;
6.打开DataGrip 2021.3软件,中间会先弹出一个注册框,我们勾选 Star trial ,登录账号后,点击 Star Trial, 先试用30天;
7.先随便新建个程工,将无限重置 30 天试用期补丁ide-eval-resetter-2.3.5.zip拖入软件中,如下图(注:小编选择的是:方式1暴力破解无限重置-补丁);
8.点击接受;
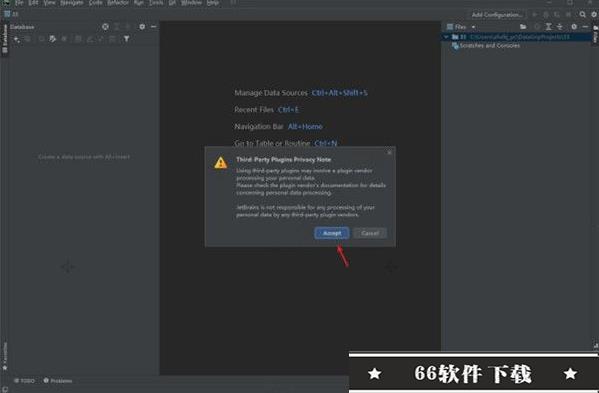
注意: zip 补丁包无需解压,激活后补丁不要移动,不要删除。
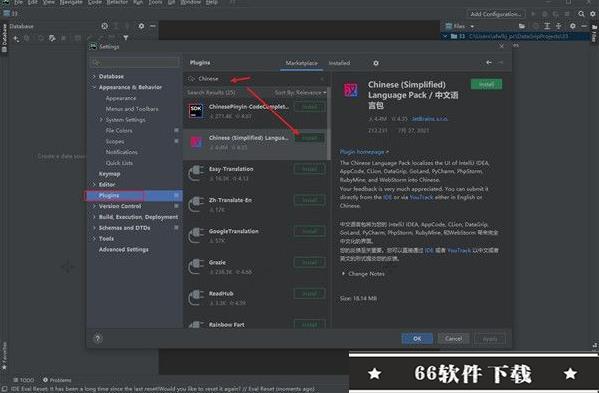
9.设置中文,软件运行后默认为英文,直接快捷键“Ctrl+ALT+S”打开“Settings -> Plugins”进行设置,在搜索框内输入“Chinese”,找到中文语言包点击Install安装;
10.DataGrip 2021.3安装成功,如何使用:重启软件,找到帮助菜单,选择Eval Reset;
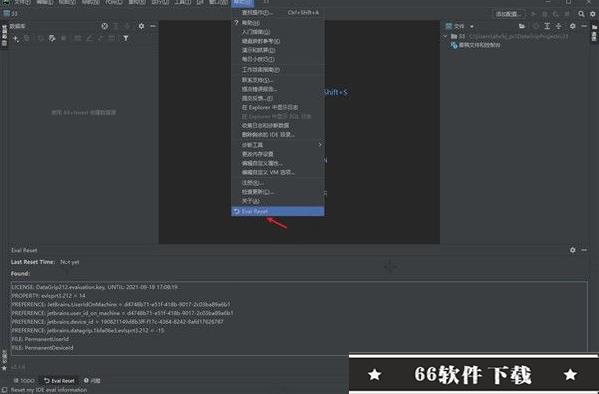
11.唤出的插件主界面中包含了一些显示信息,2个按钮,1个勾选项:
按钮:Reload 用来刷新界面上的显示信息,其中包括上一次重置30天试用期的时间。
按钮:Reset 点击会询问是否重置试用30天并重启IDE。选择Yes则执行重置操作并重启IDE生效,选择No则什么也不做。(此为手动重置方式)
软件特点
一、运行配置此概念已在我们的其他IDE中使用,现在已应用于该应用。通常,如果您要运行某些程序,则只需为其创建配置。让我们看看这如何帮助您完成特定任务。
1.运行脚本文件的配置
(1)以前,您只能一个一个地运行文件。如果文件包含依赖项并且顺序至关重要,那么这可能尤其令人沮丧。现在,您可以一次运行多个文件。
(2)选择运行多个文件将创建运行配置。在此配置中,您可以在启动之前对文件重新排序,添加新文件以及运行其他程序或配置。
(3)您的运行配置将自动保存。如果要多次运行此配置,但只想更改目标,请选中显示此页面复选框,这将为您提供每次运行配置时更改目标的选项以及其他一些选项。
2.运行代码的配置
您还可以创建一个配置,以运行保存的代码段。
3.管理运行配置
可以在导航栏或“ 运行” 菜单中找到已保存的运行配置。在这里,您将看到所有配置的列表。
二、测试框架支持
1.utPLSQL
(1)utPLSQL是用于在Oracle数据库中测试PL / SQL代码的流行框架。我们已经建立了对它的支持,这意味着您现在可以运行测试和测试包,而不必离开代码编辑器。只需单击左侧窗格中的绿色小播放按钮。
(2)每次运行都会创建一个临时配置。一段时间后,它将被删除,但是您可以在utPLSQL部分中创建永久配置。我们还添加了“按标签运行”功能。
2.数据库
该软件还添加了对 tSQLt(SQL Server的测试框架)的支持。要从数据库资源管理器运行一个或多个测试,请按 Ctrl+Shift+F10。
三、资料编辑器
1.编辑器中的结果
现在,您可以在代码编辑器中查看结果。我们希望这将很好地适合我们许多用户的工作流程。要在整个IDE中将其打开,请使用: Settings/Preferences | Database | General | Show output results in the editor。工具栏上还有一个按钮,仅在当前文件的两种模式之间切换。
2.地理检视器
要在数据编辑器中查看地理数据,请点击Gear图标 ,然后选择Show Geo Viewer。只有启用了JCEF,地理数据查看器才能工作 。在极少数情况下,启用JCEF可能会使IDE崩溃。如果您安装了使用JavaFX的插件,则可能会发生这种情况。万一发生这种崩溃,请按照以下说明恢复您的IDE:
(1)找到您的IDE的config文件夹(有关帮助,请参阅 this)。
(2)找到文件 /options/ide.general.xml
(3)从ide.general.xml中删除以下行:
3.在MongoDB中过滤数据
我们在MongoDB的数据编辑器中添加了对过滤的支持。
四、导出选项
1.导出到Excel
2.更好的可用性
在此发行周期中,我们专注于使导出更加用户友好。
五、连接性
1.新的身份验证选项
我们在PostgreSQL中添加了对pg_pass的支持如果您使用的是jTds驱动程序, 我们还增加了使用SQL Server的域凭据的功能。这曾经变得更加复杂,并且需要在“ 高级”选项卡中进行大量配置。不再是这样!
2.共享的SSH配置
现在,您可以为SSH隧道创建配置,并在许多数据源甚至项目中使用它。
六、查询控制台
1.更新预览
UPDATE语句 有一个新的预览意图操作。使用此操作将导致该软件仅使用相同的WHERE 子句运行SELECT语句。
2.轻松导航到执行设置
如果文件包含多个查询,则当您运行其中一个查询时,您将看到选择器。有些人喜欢这个选择器,但有些人则不喜欢。我们使自定义Execute操作的行为变得更加容易。
3.日期时间注入
现在,如果在字符串文字之前使用DATE进行转换,则该软件会理解此字符串包含日期,并相应地突出显示日期。如果此数据有问题,IDE也会警告您。
4.为MongoDB提供更好的编码帮助
MongoDB现在具有:
(1)集合名称的解析和完成。
(2)方法的完成。
七、导航和搜索
1.上下文数据源范围
可以在上下文数据源中搜索对象,这是您当前正在使用的数据源。可以从正在使用的控制台,数据编辑器或在数据库浏览器中选择上下文来定义上下文。如果选择多个数据源,将在所有数据源中进行搜索。
2.结构搜索
这是其他IDE移植到该应用的另一个概念。目前,我们对它的实施非常基础。您可以搜索类型,表达式和子句。
八、处理文件
1.CSV档案类型
该软件现在具有注册的* .csv文件类型。这意味着您将不再收到有关支持可用插件的CSV的通知。该软件还具有将CSV文件编辑为表格的功能。您将看到一个带有“ 另存为表格”按钮的浮动工具栏。
2.附加目录
该File | Open菜单现在重视的目录到项目中。为了清楚起见,附件目录是您在“ 文件”工具窗口中看到的目录。
3.标记为纯文本
如果您需要编辑一个非常大的脚本,现在可以将其标记为纯文本并打开以进行编辑。突出显示和编码帮助将关闭,因此您可以对其进行修改而不会造成任何性能延迟。
功能优点
1.享受使用数据库的乐趣认识该软件,这是我们的新数据库IDE,专为满足专业SQL开发人员的特定需求而设计。
2.智能查询控制台
允许您以不同的模式执行查询,并提供本地历史记录,以跟踪您的所有活动并防止您丢失工作。
3.高效的模式导航
通过相应的操作,或直接从其在SQL代码中的用法,可以按其名称跳转到任何表,视图或过程。
4.解释计划
使您可以深入了解查询的工作方式以及数据库引擎的行为,从而可以提高查询效率。
5.智能代码完成
提供了上下文相关的代码完成功能,可帮助您更快地编写SQL代码。完成了解表结构,外键,甚至是您正在编辑的代码中创建的数据库对象。
6.即时分析和快速修复
会在您的代码中检测到可能的错误,并提出最佳的解决方案以实时修复它们。使用关键字作为标识符,它将立即使您知道未解决的对象,并且始终提供解决问题的方法。
7.在SQL文件和架构中有效的重构
可以正确解析SQL代码中的所有引用,并帮助您重构它们。重命名变量或别名时,它将在整个文件中更新其用法。当您从查询中重命名对它们的引用时,数据库中的实际表名将更新。甚至还可以预览其他视图,存储过程和函数中表/视图的用法。
8.版本控制集成
我们为所有主要的版本控制系统提供统一支持:Git,SVN,Mercurial等。
新增功能
一、数据编辑器1.聚合
DataGrip 2021.3增加了显示一系列单元的 Aggregate(聚合)视图的功能。 这是一项备受期待的功能,可帮助您管理数据并免除编写额外查询的需求! 这使数据编辑器更强大、更易用,也更接近 Excel 和 Google 电子表格。
选择要查看视图的单元范围,然后点击鼠标右键并选择 Show Aggregate View(显示聚合视图)。
2.基本信息:
Aggregate(聚合)视图与 Value(值)视图共享面板,且分别拥有自己的选项卡。 您可以将此面板移动到数据编辑器底部。
您可以使用齿轮图标在此视图中显示或隐藏任何聚合。
与提取器一样,聚合也是脚本。 除了我们默认捆绑的九个脚本之外,您还可以创建和共享自己的脚本。
聚合脚本和提取器可互换。 如果您之前使用提取器仅获取一个值,现在可以将其复制到 Aggregators 文件夹并用于聚合。 它与 Extractors 文件夹相同,位于 Scratches and consoles / Extensions / Database Tools and SQL(临时文件和控制台 / 扩展程序 / 数据库工具和 SQL)中。
状态栏会显示一个聚合值,您可以选择想要的值(总和、平均值、中值、最小值、最大值等)。
3.树节点的表视图
在任意架构节点上按 F4 即可显示节点内容的表视图。 例如,您可以获得架构中所有表的表视图:
或者,您也可以查看表列的表视图:
您可以使用此视图隐藏/显示列、将数据导出为多种格式,以及使用文本搜索。 另外,以下导航操作也适用:
Ctrl+B 显示 DDL。
F4 显示数据。
Alt+Shift+B 在数据库树中高亮显示对象。
4.独立拆分
如果拆分编辑器后再次打开同一个表,则两个数据编辑器窗口现在将完全独立。 然后,您可以设置不同的筛选和排序选项,用于比较和处理数据。 筛选和排序先前是同步的,对操作来说不是很理想。
5.自定义字体
您可以在 Database | Data views | Use custom font(数据库 | 数据视图 | 使用自定义字体)下选择一种专用字体来显示数据。
6.通过多个值进行外键导航
在数据编辑器中,您现在可以选择多个值并导航到相关数据。
7.默认排序设置
您可以通过 ORDER BY 或 client-side 定义表格的默认排序方法:后者不运行任何新查询并且仅对当前页面进行排序。 该设置位于 Database | Data views | Sorting | Sort via ORDER BY(数据库 | 数据视图 | 排序 | 通过 ORDER BY 排序)中。
8.二进制数据的显示模式
16 字节数据现在默认显示为 UUID。 您也可以自定义二进制数据在数据编辑器列中的显示方式。
二、将数据库保留在 VCS 中
1.映射 DDL 数据源和真实数据源
上一版本引入了基于真实数据源生成 DDL 数据源的功能,此版本是其逻辑延续。 现在,此工作流已获得完全支持。 您可以:
2.将 DDL 数据源映射到真实数据源。
在两个方向上比较和同步。
请注意,DDL 数据源是一种虚拟数据源,其架构基于一组 SQL 脚本。 将这些文件存储在版本控制系统中即可将数据库保留在 VCS 下。
数据配置属性中新增了 DDL mappings(DDL 映射)选项卡,用于定义映射到各 DDL 数据源的真实数据源。
如果您想进一步了解这些新增功能在日常 VCS 流程中的作用,请阅读本文。
3.新的数据库差异窗口
要将您的 DDL 数据源与真实数据源比较和同步,请使用上下文菜单并从 DDL Mappings 子菜单中选择 Apply from...(应用自…)或者 Dump to...(转储至…)。
这一全新窗口具有更好的 UI,并且在右侧窗格中清楚显示了执行同步后您将获得的结果。
右侧窗格中的图例显示了不同颜色潜在结果的含义:
绿色和斜体:对象将被创建。
灰色:对象将被删除。
蓝色:对象将被更改。
Script preview(脚本预览)选项卡显示结果脚本,可在新控制台中打开或从此对话框运行。 此脚本的结果是应用变更,使右侧数据库(目标)成为左侧数据库(源)的副本。
除了 Script preview(脚本预览)选项卡,底部窗格中还有两个选项卡:Object Properties Diff(对象属性差异)和 DDL Diff(DDL 差异)。 它们显示源数据库和目标数据库中对象的特定版本之间的差异。
注意:如果您只想比较两个架构或对象,应选择两者并按 Ctrl + D。
重要提示!差异查看器仍在全速开发中。 由于每个数据库都有自己的特定功能,部分对象可能会在显示上不同,但实际却相同。 这可能是因为类型别名或在生成中省略了默认属性。 如果您遇到此错误,请将其报告给我们的跟踪器。
4.文件相关操作
文件的所有操作也均可用于 DDL 数据源元素。 例如,您可以从数据库资源管理器中删除、复制或提交与架构元素相关的文件。
5.自动同步
打开此选项后,您的 DDL 数据源将随着相应文件的更改而自动刷新。 这是默认行为,但现在您可以选择将其禁用。
禁用后,源文件中的变更将不会自动反映在 DDL 数据源中,您需要点击 Refresh(刷新)进行应用。
6.设置默认架构和数据库
在 Default schemas/databases(默认架构/数据库)窗格中,您可以定义数据库和架构的名称,它们将在 DDL 数据源中显示。 DDL 脚本通常不包含名称,在这些情况下,默认会为数据库和架构设置虚拟名称。
三、连接性
1.意外空格警告
如果除 User(用户)或 Password(密码)之外的值有前导或尾随空格,将在您点击 Test Connection(测试连接)时发出警告。
2.LocalDB 作为专用数据源 SQL Server
SQL Server LocalDB 在驱动程序列表中有自己的专用驱动程序。 这意味着它具有单独类型的数据源,应该用于 LocalDB。 它的作用:
3.LocalDB 连接可供进一步探索。
只要在驱动程序选项中为可执行文件设置一次路径,它就将应用于所有数据源。
4.Kerberos 身份验证 Oracle、SQL Server
现在可以在 Oracle 和 SQL Server 中使用 Kerberos 身份验证。 您需要使用 kinit 命令为主体获取初始票证授予票证,将在您选择 Kerberos 选项时使用该票证。
5.启用 DBMS_OUTPUT Oracle、IBM Db2
Options(选项)选项卡中新增的这一选项允许您为新会话默认启用 DBMS_OUTPUT。
6.More options(更多选项)按钮
我们添加了一个 More Options(更多选项)按钮,为连接提供了更多配置选项。 当前选项包括为 Snowflake 连接添加 Schema(架构)和 Role(角色)字段,以及使 SSH 和 SSL 更易被发现的两个配置菜单项。
7.专家选项
Advanced(高级)选项卡加入了一个 Expert options(专家选项)列表。 除了打开 JDBC 内省器的选项(请在使用前联系我们的支持团队!),还有以下数据库专用选项:
Oracle:Disable incremental introspection(禁用增量内省)、Fetch LONG values(获取 LONG 值)和 <0>Introspect server objects(内省服务器对象)
SQL Server:Disable incremental introspection(禁用增量内省)
PostgreSQL(和类似选择):Disable incremental introspection(禁用增量内省)和 Do not use xmin in queries to pgdatabase(不在对 pgdatabase 的查询中使用 xmin)
SQLite:Register REGEXP function(注册 REGEXP 函数)
MYSQL:Use SHOW/CREATE for source code(为源代码使用 SHOW/CREATE)
ClickHouse:Automatically assign sessionid(自动分配 sessionid)
四、内省
1.内省级别 Oracle
Oracle 用户经常遇到软件的内省问题,在数据库和架构较多时会耗费很长时间。 内省流程可获取数据库元数据,例如对象名称和源代码。 需要它来提供快速的编码辅助、导航和搜索。
Oracle 系统目录较为缓慢,如果用户没有管理员权限,内省会更慢。 我们已经尽最大努力对获取元数据的查询做出了优化,但仍然有一些局限并非我们尽力就能左右。
我们了解到对于大多数日常工作,甚至对于有效的编码辅助来说,对象源其实都不需要加载。 在许多情况下,仅具有数据库对象名称就足以提供正确的代码补全和导航。 因此,我们为 Oracle 数据库引入了三个级别的内省:
级别 1:所有支持对象的名称及其签名,不包括索引列和私有软件包变量的名称
级别 2:除源代码外的所有内容
级别 3:所有内容
内省在级别 1 上最快,在级别 3 上最慢。
使用上下文菜单根据需要切换内省级别:
内省级别可针对架构或整个数据库设置。 架构从数据库继承内省级别,但也可独立设置。
内省级别由位于数据源图标旁的药丸状图标表示。 药丸越满,级别就越高。 蓝色图标表示内省级别为直接设置,灰色表示继承。
将链接服务器和数据库链接映射到数据源 SQL Server、Oracle
您可以将 SQL Server 中的链接服务器或 Oracle 中的数据库链接映射到任何现有数据源。
当外部对象被映射到数据源时,代码补全和解析将适用于使用这些外部对象的查询。
2.隐藏系统架构和模板数据库 PostgreSQL
内部系统架构(如 pg_toast 或 pg_temp)和模板数据库过去在架构列表中隐藏。 现在可通过 Schemas(架构)选项卡中的相应选项显示。
3.支持流 Snowflake
现在,除了表和视图之外,流也会显示在数据库视图中。
4.分布式表 ClickHouse
分布式表现在位于数据
五、查询控制台
1.布尔表达式检查
一位用户在 Twitter 上谈到了自己的不幸遭遇:他在生产数据库上以条件 WHERE id - 3727(而不是 =)执行了 UPDATE 查询,然后数百万条记录都被更新了!
我们也没想到 MySQL 会允许这样的情况发生,但世事就是如此难料。 当然,发现这个问题后,我们团队就为此添加了一项检查。 接下来就请了解 WHERE 和 HAVING 子句中布尔表达式的检查。
如果表达式似乎不是明确的布尔值,会将其高亮显示为黄色,并在您运行此类查询之前发出警告。 它适用于 ClickHouse、Couchbase、Db2.H2.Hive/Spark、MySQL/MariaDB、Redshift、SQLite 和 Vertica。 在所有其他数据库中,这将被高亮显示为错误。
2.提取查询的函数
现在,查询可以被提取为表函数。 为此,首先选择查询,调用 Refactor(重构)菜单,然后使用 Extract Routine(提取例程)。
3.JOIN 基数内嵌提示
新的内嵌提示将说明 JOIN 子句的基数。 三种可能的选项是:一对一、一对多和多对多。 如果您想将其关闭,可以调整 Preferences | Editor | Inlay Hints | Join cardinality(偏好设置 | 编辑器 | 内嵌提示 | Join 基数)中的设置。
4.数据库名称的代码补全 MongoDB
使用 getSiblingDB 补全数据库名称,使用 getCollection 补全集合名称。
此外,如果是从通过 getCollection 定义的集合中使用字段名称,字段名称会被补全和解析。
五、Services(服务)工具窗口
1.输出中的时间戳默认隐藏
根据此请求,默认不再为查询输出显示时间戳。 如果要恢复先前的行为,可以在 Database | General | Show timestamp for query output(数据库 | 常规 | 为查询输出显示时间戳)中调整设置。
2.新激活设置
如果在窗口模式下使用 Services(服务)工具窗口,它默认将被隐藏在 IDE 之后。 使用新设置,可在每次运行查询时向其转移焦点,让它在查询完成后出现。
此外,如果您在其他控制台中完成较长的查询时感觉会受到干扰,可激活 Services(服务)工具窗口中的相应选项卡,选中 Activate Services output pane for selected query console only
六、导入/导出
1.新的数据导入 UI
导入 .csv 文件或复制表/结果集时,您将看到以下改进:
您可以选择现有表或创建新表。
您可以在导入对话框中更改目标架构。 如果复制表或结果集,则不会出现目标的专用对话框。
目标被保存为每个架构的默认值。 因此,如果您是持续从一个特定架构复制到另一个架构,则无需每次都选择目标。
2.First row is header(第一行是标题)自动检测
当您打开或导入 CSV 文件时,会自动检测第一行是否为标题以及是否包含列名称。
3.CSV 文件中的自动列类型
现在可以检测 CSV 文件中的列类型。 这可以让您按数值对数据进行排序。 过去,它们会被视为文本,排序不够直观。
七、其他
1.新的 Bookmarks(书签)工具窗口
我们以前有两个非常相似的实例:Favorites(收藏夹)和 Bookmarks(书签)。 由于两者之间的区别有时会造成困惑,我们决定改为只使用 Bookmarks(书签)。 我们重新设计了此功能的工作流,并为其创建了一个新的工具窗口。
从现在开始,您标记为重要(在 macOS 上使用 F3,在 Windows/Linux 上使用 F11)的所有对象或文件都将位于新的 Bookmarks(书签)工具窗口中。
热门点评:
探索e族:
DataGrip 2021.3应该是近些年来比较优异的几款工具了,估计以后也很难会被超越了,丰富而具有特色的功能,太强了,抢到令人发指
DataGrip 2021.3其他版本下载
软件特别提示(使用须知)百度网盘提取码: xefy
图像处理哪个好
-
Vectorworks 2022 SP0 中文破解版(附破解教程)

123MB | 中文
-

995MB | 中文
-
Burp Suite 2022 中文破解版(附图文激活教程)

554MB | 中文






 Fr
Fr An
An Br
Br LR
LR Au
Au Premiere
Premiere Prelude
Prelude Character
Character AE
AE ps
ps